Período: 27/01/2023 – 16/02/2023
Durante essa Sprint, a equipe teve o objetivo de realizar a integração com a API do PJe 2x, refatorar e melhorar os códigos do MVP, realizar testes com a equipe da JFPE, reunião com JFRN e fazer o deploy da nova versão da ferramenta com o avanço do modelo de ML.
Realizamos novas pesquisas e avanços na API do PJe 2x, agora atingimos um nível onde conseguimos autenticar o usuário e fazer uma requisição de processo, a partir do Postman (passo fundamental para a passagem dos códigos para o nosso serviço). Nesta consulta, conseguimos o retorno de dados do processo. Porém, ainda não é o avanço que desejamos, pois a consulta é de certo modo filtrada demais, para o nosso objetivo. Utilizamos um endpoint já mapeado pela equipe da JFPB (PJe Mobile) e atende uma demanda específica de “Tarefas/Assinatura”. Com esse endpoint conseguimos obter as informações de processos, mas essa busca fica limitada a escolhermos uma vara específica e um perfil de usuário específico, por exemplo “Diretor de Secretaria da 11ª Vara Cível- PE”. É possível listar todos os processos que estão com esse usuário.
Pensando no aproveitamento e na usabilidade do produto, essa pesquisa tão refinada não ajudaria, precisamos de uma consulta mais abrangente.
Para isso, fizemos a integração (em formato de consulta de processo, para validação e teste) com a API do PJe 1x, disponibilizada pelo Tribunal.

(Número e informação das partes apagadas)
Com a seleção da instância e a entrada do número do processo, o sistema fará automaticamente a autenticação, a coleta do token e a requisição com os parâmetros escolhidos, retornando para o usuário uma janela modal com as informações daquele processo, cadastradas no PJe. Dessa forma, validamos nosso MVP no sentido de que com a integração da API, podemos bater as informações cadastradas na base com as informações colhidas da petição, inclusive o assunto.
Tivemos também reunião com a equipe da JFRN, onde conseguimos apresentar a ferramenta e demonstrar o uso. Na ocasião colhemos as primeiras impressões da equipe sobre o projeto e apontamentos relevantes como melhoria. O tamanho limite do arquivo PDF inserido, por exemplo. É algo que traremos para a análise e poderemos implementar.
Nosso modelo de ML também sofreu incremento. Agora temos a inserção de mais dois assuntos treinados para consulta, Aposentadoria por Invalidez e Auxílio Doença.

Essas classes estão sendo utilizadas no dataframe, de forma desbalanceada usando a técnica de undersampling.
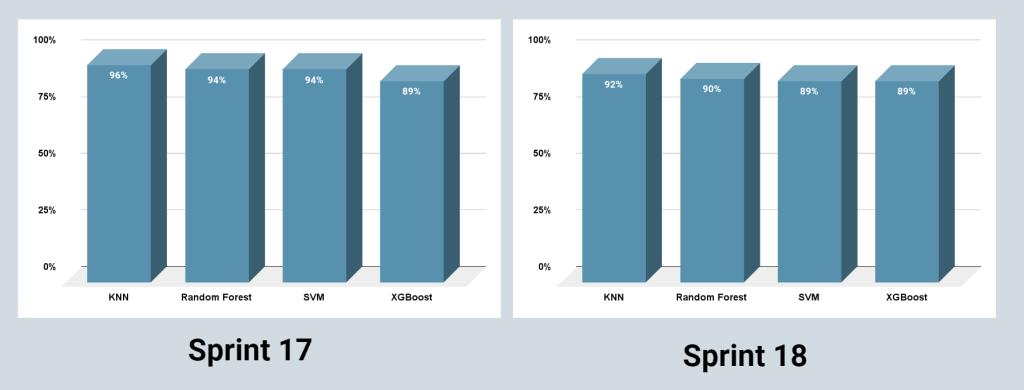
Comparando com a Sprint 17, observamos que o modelo KNN permanece com uma boa performance em relação aos outros. Mesmo com a queda no percentual de acurácia, devido a chegada e novas petições e assuntos, o modelo continua apresentando resultados positivos e se mantém acertando as indicações de assunto. O KNN está trabalhando com 650 features e
stemmatização das palavras (apenas o radical da palavra) uni-gram, bi-gram e tri-gram.
Seguimos para a Sprint 19 com a expectativa de entregar a ferramenta mais refinada na experiência do usuário e adicionar uma página para a Triagem de petições com PJe 1x, utilizando a integração já validada.
© 2026 Residência TI. Construído usando o WordPress e o Highlight Theme